the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 01 Oct 2020
| 01 Oct 2020
DeerLab: a comprehensive software package for analyzing dipolar electron paramagnetic resonance spectroscopy data
Luis Fábregas Ibáñez
Gunnar Jeschke
Dipolar electron paramagnetic resonance (EPR) spectroscopy (DEER and other techniques) enables the structural characterization of macromolecular and biological systems by measurement of distance distributions between unpaired electrons on a nanometer scale. The inference of these distributions from the measured signals is challenging due to the ill-posed nature of the inverse problem. Existing analysis tools are scattered over several applications with specialized graphical user interfaces. This renders comparison, reproducibility, and method development difficult. To remedy this situation, we present DeerLab, an open-source software package for analyzing dipolar EPR data that is modular and implements a wide range of methods. We show that DeerLab can perform one-step analysis based on separable non-linear least squares, fit dipolar multi-pathway models to multi-pulse DEER data, run global analysis with non-parametric distributions, and use a bootstrapping approach to fully quantify the uncertainty in the analysis.
- Article
(3836 KB) - Full-text XML
-
Supplement
(511 KB) - BibTeX
- EndNote





Dipolar electron paramagnetic resonance (EPR) spectroscopy encompasses a growing family of techniques for determining distributions of nanometer-scale distances between unpaired electrons. These distance distributions provide valuable information for the structural characterization of macromolecular or biological systems that is complementary to information obtained by other techniques. For structurally disordered or highly complex systems, where established techniques may fail, such distance distributions provide unique information. The family of dipolar EPR spectroscopy techniques includes double electron–electron resonance (DEER) (Milov et al., 1981, 1984; Pannier et al., 2000a, b), double quantum coherence (DQC) (Saxena and Freed, 1996, 1997; Borbat et al., 2013), relaxation-induced dipolar modulation enhancement (RIDME) (Kulik et al., 2001; Milikisyants et al., 2009), single-frequency technique for refocusing (SIFTER) (Jeschke et al., 2000), and several other related techniques (Borbat et al., 2013; Di Valentin et al., 2014; Hintze et al., 2016; Pribitzer et al., 2017; Borbat and Freed, 2017; Doll and Jeschke, 2017; Milikisiyants et al., 2018). All of them provide a time-domain signal that depends on the dipolar interaction between pairs of electrons. From this time-domain signal, the distance distribution is inferred.
Due to its mathematical nature, the robust inference of distance distributions from noisy dipolar EPR spectroscopy data is not straightforward. Many approaches have been proposed to tackle this problem (Pannier et al., 2000a; Jeschke et al., 2002, 2004, 2006; Bowman et al., 2004; Chiang et al., 2005a, b; Sen et al., 2007; Brandon et al., 2012; Stein et al., 2015; Dzuba, 2016; Matveeva et al., 2017; Srivastava and Freed, 2017; Edwards and Stoll, 2016; Rein et al., 2018; Timofeev et al., 2018; Worswick et al., 2018; Hustedt et al., 2018; Edwards and Stoll, 2018; Fábregas Ibáñez and Jeschke, 2019, 2020; Sweger et al., 2020), each with its pros and cons. Some of these methods have found widespread use, via software packages such as DeerAnalysis (Jeschke et al., 2006), GLADD/DD (Brandon et al., 2012), and LongDistances (Altenbach, 2020).
However, there are several major challenges with the current situation. (i) A comparative assessment of the relative merits of various methods is missing. (ii) Many methods have been argued based on anecdotal evidence from small datasets, and their performance has not been assessed comprehensively. (iii) Reproducibility of analysis results is very limited due to the lack of common platforms for data sharing and data analysis.
To remedy this situation, we introduce DeerLab, an open-source software for data analysis in dipolar EPR. It is based on the Python programming language and consists of a collection of modular functions, analogous to EasySpin (Stoll and Schweiger, 2006) and Spinach (Hogben et al., 2011). This has several distinct advantages over a graphical user interface (GUI). (i) It allows for very flexible workflow designs, easily adapting to different experimental situations. (ii) All existing methods can be directly compared on a single platform. (iii) Automation and processing of large datasets become straightforward. (iv) Scripted data analysis improves reproducibility and collaboration. (v) It provides a foundation for implementing new methodologies. (vi) It can be embedded into other software, such as tools for protein structure modeling based on distance distributions (Jeschke, 2018). The disadvantage is an accessibility barrier for potential users without programming skills. This disadvantage can be remedied by building a dedicated GUI for standard workflows as an additional software layer.
This paper is structured as follows. We start by summarizing the theoretical basics of dipolar EPR spectroscopy. Then, we illustrate the functionality of DeerLab through a series of examples. First, we show how to reproduce well-established workflows such as Tikhonov regularization and multi-Gauss fits. We then demonstrate how DeerLab can perform one-step analysis based on separable non-linear least-squares optimization, fit dipolar multi-pathway models to multi-pulse DEER data, and run global analysis with non-parametric distributions. Finally, several sections are dedicated to important aspects of uncertainty analysis, including the use of bootstrapping. The DeerLab scripts for generating all figures, as well as the corresponding distance distributions and dipolar signals, are available in the supporting information.
This section summarizes the central theoretical concepts of dipolar EPR spectroscopy that DeerLab is based on. For more details, see Jeschke (2012, 2016). The theory is limited to spins with isotropic g-values, without any orientation selection, at most two spins per protein, no exchange coupling, weak dipolar coupling, and no conformer-dependent relaxation rates.
Dipolar EPR spectroscopy techniques measure the magnetic dipole–dipole couplings between spins via the modulation of the amplitude V(t) of a spin echo as a function of the position t of one or more pump pulses. The echo amplitude is modeled as (Milov et al., 1981)
where V0 is the echo amplitude in the absence of any pump pulses, Vintra describes the pump-pulse-induced modulation due intra-molecular dipolar couplings, and Vinter describes the modulation due to intermolecular couplings. V0 is a constant prefactor that we set to one from now on in order not to complicate the notation unnecessarily. DeerLab takes V0 into account as a fitting parameter.
The product of intra- and inter-molecular dipolar modulations can be written in a general form as
P(r) is the distribution of intra-molecular spin–spin distances r on the protein or other complex, normalized such that .
K(t,r) is the kernel that captures how the complete dipolar modulation is determined by the distance distribution. It includes the inter-molecular modulation (Fábregas Ibáñez and Jeschke, 2020). For standard four-pulse DEER it is
Here, λ is the modulation depth. K0 is the elementary kernel
with the dipolar coupling constant
where ge is the g-value of the free electron, μB the Bohr magneton, μ0 the magnetic constant, and ℏ the reduced Planck constant. K0 assumes full orientation averaging and unlimited excitation bandwidth. The subscript 0 distinguishes this elementary kernel from more general kernels such as Eq. (3).
Vinter(t,λ) represents the inter-molecular modulation and is commonly called the background. It can be modeled as a stretched-exponential function
where κd is a decay rate constant and d is the dimensionality (Kutsovsky et al., 1990; Milov et al., 1998; Jeschke et al., 2002). Other background models are possible (Kattnig et al., 2013).
Experimentally, the echo amplitude is measured only for a discrete set of usually equally spaced time points ti, yielding a dipolar signal vector V with n elements Vi=V(ti). For numerical analysis, P(r) is represented as a discrete distance distribution vector P with m elements Pj=P(rj) at equally spaced rj. With this, Eq. (2) reads
where K is the n×m kernel matrix with elements , and Δr is the increment in the distance domain.
Experimental data Vexp deviate from in Eq. (1) due to presence of noise. From experiments, it was found that the noise distribution in DEER signals is well approximated by an uncorrelated Gaussian distribution with zero mean and constant variance (Edwards and Stoll, 2016):
Inferring the distance distribution from the dipolar signal formally requires inversion of the kernel matrix
However, K is generally badly ill-conditioned (it has an extremely large condition number). This renders the inverse problem ill-posed, and the results obtained by Eq. (9) are highly unstable, erratic, and unreliable, especially in the presence of noise. Because of the ill-posedness, inferring distance distributions from the dipolar signals poses a major challenge in dipolar EPR spectroscopy data analysis.
Currently, two families of methods are commonly used in dipolar EPR spectroscopy data analysis. They differ in whether the distance distribution is represented as a parametric model or as a non-parametric model. Both methods stabilize the solution and are widely used since they are simple and often effective.
In the following, we discuss these two families of methods from the perspective of DeerLab.
3.1 Non-parametric distributions
If P is represented as a non-parametric vector, regularization methods are used to determine the solution. If background and modulation depth are known and fixed, the associated regularized optimization problem has the form
The first term represents the sum of squared residuals, i.e., χ2 without normalization by the noise variance, which we assume constant across the signal (see Eq. 8). It quantifies the quality of the fit of the model to the data. The second term is an additional penalty term that, together with the non-negativity constraint P≥0, stabilizes the solution. The regularization matrix L is a numerical approximation of a differential operator to impose smoothness, and α is the regularization parameter, which controls the balance between data agreement and regularization.
Regularization methods differ in the choice of the penalty norm ℛ. Tikhonov regularization (Tikhonov, 1963) was the first regularization approach introduced for dipolar data analysis (Bowman et al., 2004; Chiang et al., 2005a; Jeschke et al., 2004). Other approaches such as total variation (TV), Huber regularization, and Osher's Bregman-iterated regularization are beneficial in certain cases (Fábregas Ibáñez and Jeschke, 2019).
In the absence of the non-negativity constraint, the problem in Eq. (10) could be solved directly by , with the α-dependent regularized pseudoinverse of the kernel matrix
in the case of Tikhonov regularization. However, due to the non-negativity constraint, this is not possible, and Eq. (10) is solved using non-negative least-squares optimization algorithms (Lawson and Hanson, 1974; Bro and Jong, 1997; Chen and Plemmons, 2009). will be useful for uncertainty analysis (see Sect. 9).
The selection of α has been optimized for a large test set in previous work (Edwards and Stoll, 2018) and replicated (Fábregas Ibáñez and Jeschke, 2019), revealing that selection methods such as the Akaike information criterion (AIC) (Akaike, 1974) or general cross-validation (GCV) (Golub et al., 1979) can be superior to L-curve criteria (Hansen, 2000; Chiang et al., 2005a; Jeschke et al., 2006) if Gaussian white noise is the only source of error.
DeerLab provides a flexible regularization framework including all the aforementioned α-selection, non-iterated and iterated regularization methods, as well as a selection of solvers. In particular, implementation of Huber and TV regularization is much improved compared to our original study (Fábregas Ibáñez and Jeschke, 2019), such that these now perform similarly to Tikhonov regularization, invalidating the conclusions on the under-performance of Huber and TV regularization from that initial work.
Figure 1 shows how regularization approaches can be compared using DeerLab. Figure 1a presents an example of a low-noise dipolar signal processed via Tikhonov, TV and Osher's Bregman (Tikhonov) iterated regularization. All methods using the AIC for α-selection yield similar results. Figure 1b illustrates how regularization methods perform in the presence of strong noise. In such cases more differences arise between the different methods.
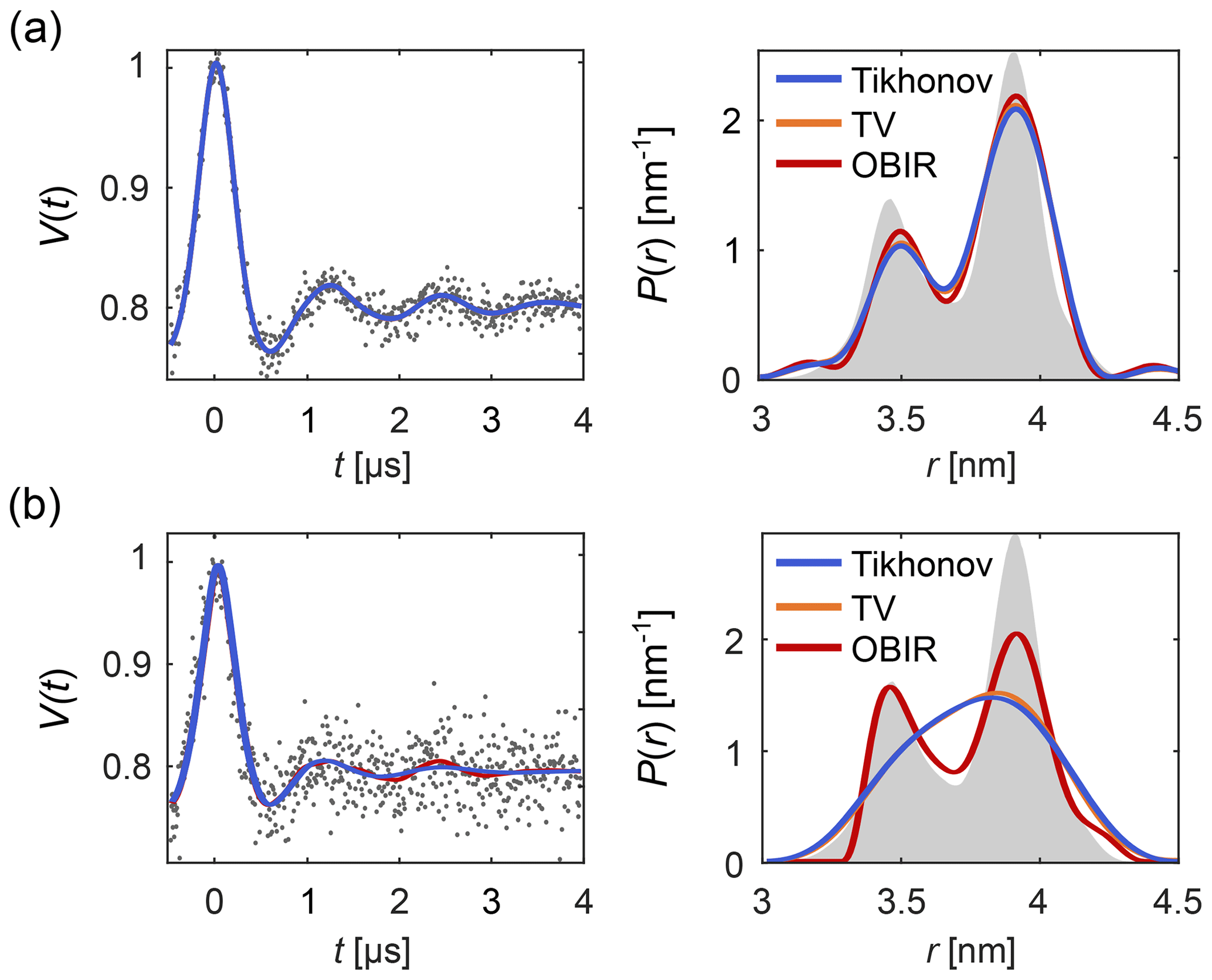
Figure 1Analysis of background-free dipolar signals with regularization. A distance distribution is fit to (a) a low-noise signal and (b) a high-noise signal using Tikhonov regularization (blue), TV regularization (orange), and Osher's Bregman-iterated (OBIR) regularization (red). In all cases, the AIC was used for the selection of the regularization parameter (see Fig. S1). The input data (simulated) are shown as grey dots and the ground truth distance distribution is shown as grey shaded areas.
The outcomes of regularization analysis depend strongly on the choice of penalty norm, regularization operator, and α. For the remainder of this work, if not specified otherwise, we will use the Tikhonov penalty equipped with the second-order difference operator L2 and the AIC for α-selection.
3.2 Parametric models
In an alternative representation, P is described as a parametric model P[θ] with , where θ is a vector of a small number of parameters. This is fit to the data using
Since solving the inverse problem by fitting a non-linear parametric model with only a few parameters is a well-conditioned problem, it can be solved without the need for regularization.
While bimodal Gaussian distributions were the first parametric models (Pannier et al., 2000a), the idea was generalized to a linear combination of N Gaussian distributions (Sen et al., 2007) (which we will refer to as a multi-Gauss model)
where ai are the amplitudes and pi are the normalized Gaussian basis functions parameterized by their center distances and widths σi. Other parameterizations of the amplitudes can be used (Brandon et al., 2012; Stein et al., 2015).
To determine the optimal number N of Gaussians in the multi-Gauss model, Sen et al. (2007) proposed a statistical F-test, while Stein et al. (2015) and Hustedt et al. (2018) introduced the corrected Akaike information criterion (AICc) (Sugiura, 1978; Hurvich and Tsai, 1989) and the Bayesian information criterion (BIC) (Schwarz, 1978). Two more recent approaches utilize Monte Carlo simulations to determine the optimal multi-Gauss model (Dzuba, 2016; Timofeev et al., 2018). Parametric models are not limited to Gaussian basis functions. Many other basis function types (or mixtures thereof) can be employed, e.g., 3D Rice distributions (Domingo Köhler et al., 2011), spherical distributions (Ionita et al., 2008; Kattnig and Hinderberger, 2013), random-coil models (Fitzkee and Rose, 2004), or worm-like chain models (Wilhelm and Frey, 1996).
In a milestone for parametric modeling, Brandon et al. expanded the use of parametric models to include the modulation depth and a stretched-exponential background in the analysis of the signal in their software GLADD/DD (Brandon et al., 2012; Stein et al., 2015). This results in a time-domain parametric model
In this, the parameter vector θ includes not only the distance distribution parameters θP, but also the modulation depth λ and the background parameters θB. In general, a parametric time-domain model can be fit to the experimental data by solving
DeerLab expands upon this, allowing the design and fitting of any kind of time-domain or distance distribution parametric model. Automated multi-Gauss fitting and model selection using AIC, BIC, and other metrics are provided as well. In Fig. 2 we provide such an example of multi-Gauss fitting with DeerLab. The signal is fit using the time-domain model Eq. (14) and a varying number of Gaussians as the distance distribution model. Model selection based on the AIC determines the most parsimonious number of Gaussians, with a decent fit of the distance distribution.
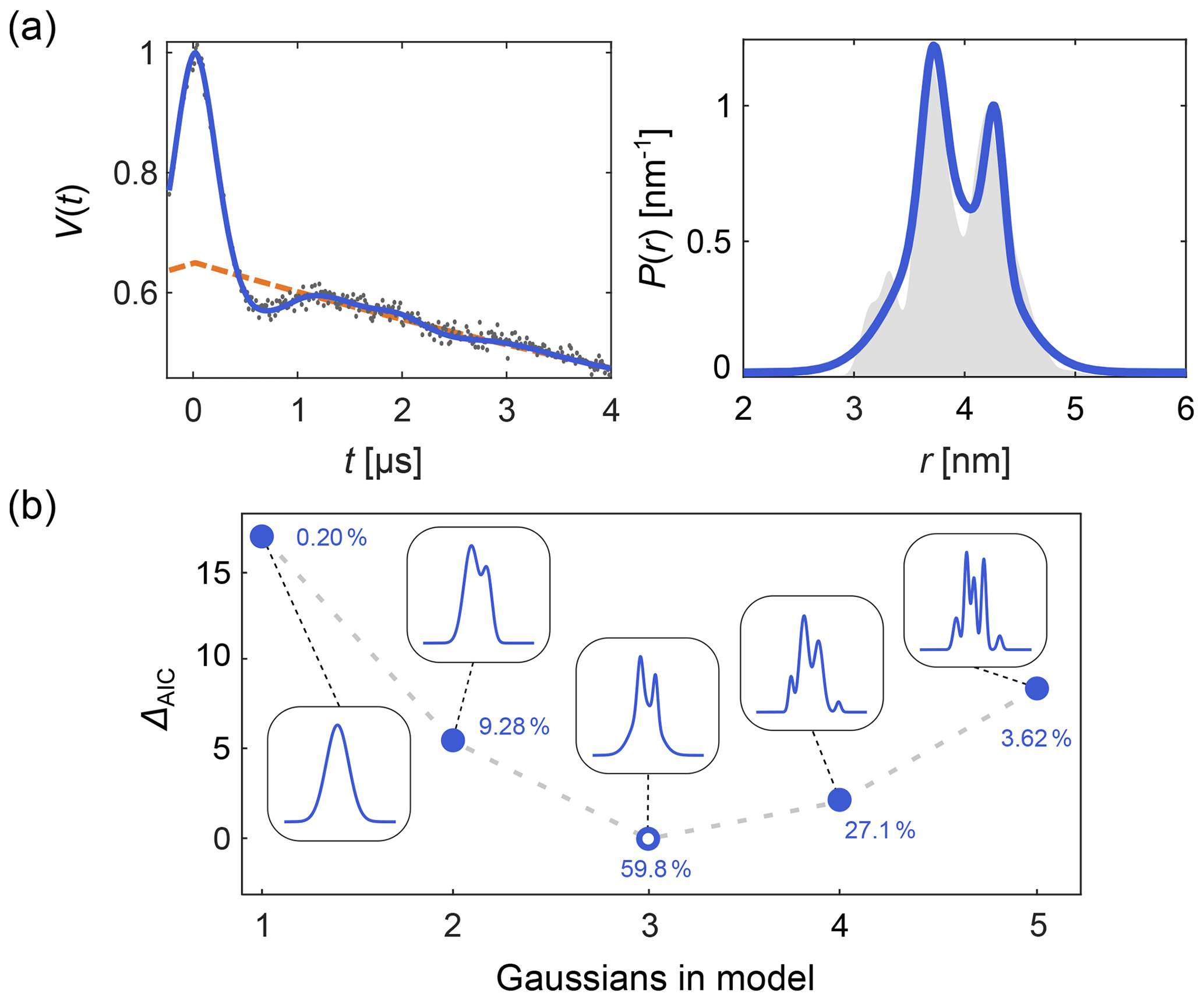
Figure 2Time-domain multi-Gauss fitting of a simulated four-pulse DEER signal. (a) The data are given as grey dots, the ground truth distance distribution as a shaded area, and the corresponding fits of a 3-Gauss model as blue lines. The background fit is given as dashed orange line. (b) The difference in AIC values as a function of the number of Gaussians is shown in blue, and the corresponding fits are given in the insets. The differences ΔAIC are relative to the model with the lowest AIC value. The corresponding Akaike weights (see Sect. 10) are given next to each model. The model with the lowest AIC value (i.e., largest Akaike weight) is selected as the optimal model.
It is, however, crucially important to keep in mind that approaches based on parametric models may suffer from selection bias, i.e., the bias introduced by limiting the analysis to a specific family of models and by using a particular criterion for model selection within that family (Freedman, 1983; Lukacs et al., 2009). Parametric model fits may also be affected by confirmation bias, i.e., the tendency to process data in a way that matches one's preconceptions and avoids contradiction of prior belief (Nickerson, 1998).
Neither parametric model fitting nor regularization is ideal. Parametric models can be fit directly to the full time-domain signal but are strongly limited by how well they can approximate the ground truth distribution. On the other hand, regularization yields non-parametric distance distributions that accommodate a much larger range of ground truths, but regularization cannot directly include other parameters such as the background and the modulation depth.
With regularization methods, it is therefore common practice to use a two-step approach: (1) fit a parametric background model to the time-domain signal and correct the signal by the fitted background (either by division or subtraction) and (2) apply regularization to the background-corrected signal. Software based on this approach includes DeerAnalysis (Jeschke et al., 2006) and LongDistances (Altenbach, 2020). Including the fitted background in the kernel for step (2), as in Eq. (3), also does not eliminate the need for the two-step approach (Fábregas Ibáñez and Jeschke, 2020).
The two-step analysis as done in DeerAnalysis is sub-optimal, because the background fit in step (1) relies on the assumption that the oscillation periods in the time-domain signal are much shorter than the overall signal length. Many experimentally observed signals do not satisfy this assumption. Therefore, the two-step analysis cannot robustly process these types of signals.
The most desirable approach is to simultaneously fit both the time-domain parameters θ and a non-parametric distance distribution P to the time-domain signal Vexp in one step, i.e.,
with the regularized objective function
Equation (16) can be solved using a variety of constrainable non-linear optimization algorithms by combining θ and P into a single parameter vector and applying all the constraints for θ and P (Altenbach, 2020). However, this does not take full advantage of the special structure of the problem, i.e., that it is a penalized least-squares problem with a model for V that is linear in P and non-linear in θ.
To take advantage of this structure, DeerLab implements a nested subspace optimization algorithm based on separable non-linear least-squares (Budil et al., 1996; Golub and Pereyra, 2003; Sima and Van Huffel, 2007). It separates the θ and P spaces and uses a non-linear least-squares algorithm to solve
where P[θ] is the optimal non-parametric distance distribution for a given θ, determined via regularization
as in Eq. (10), using a dedicated non-negative linear least-squares algorithm. (Note that P is now a parametric model since it depends on θ, although this includes only modulation depth and background parameters.) Once θfit is obtained, Pfit is calculated as P[θfit]. The algorithm is iterative and is illustrated in Fig. 3. It starts with an initial guess for θ and determines the associated P from Eq. (19). This P is then used by the algorithm of Eq. (18) to determine the next θ, which is then used again by the algorithm in Eq. (19) to get the next P[θ], and so on until convergence is reached. The optimization in Eq. (19) can utilize any form of regularization, and it can be run with a fixed regularization parameter α or optimize it each time.
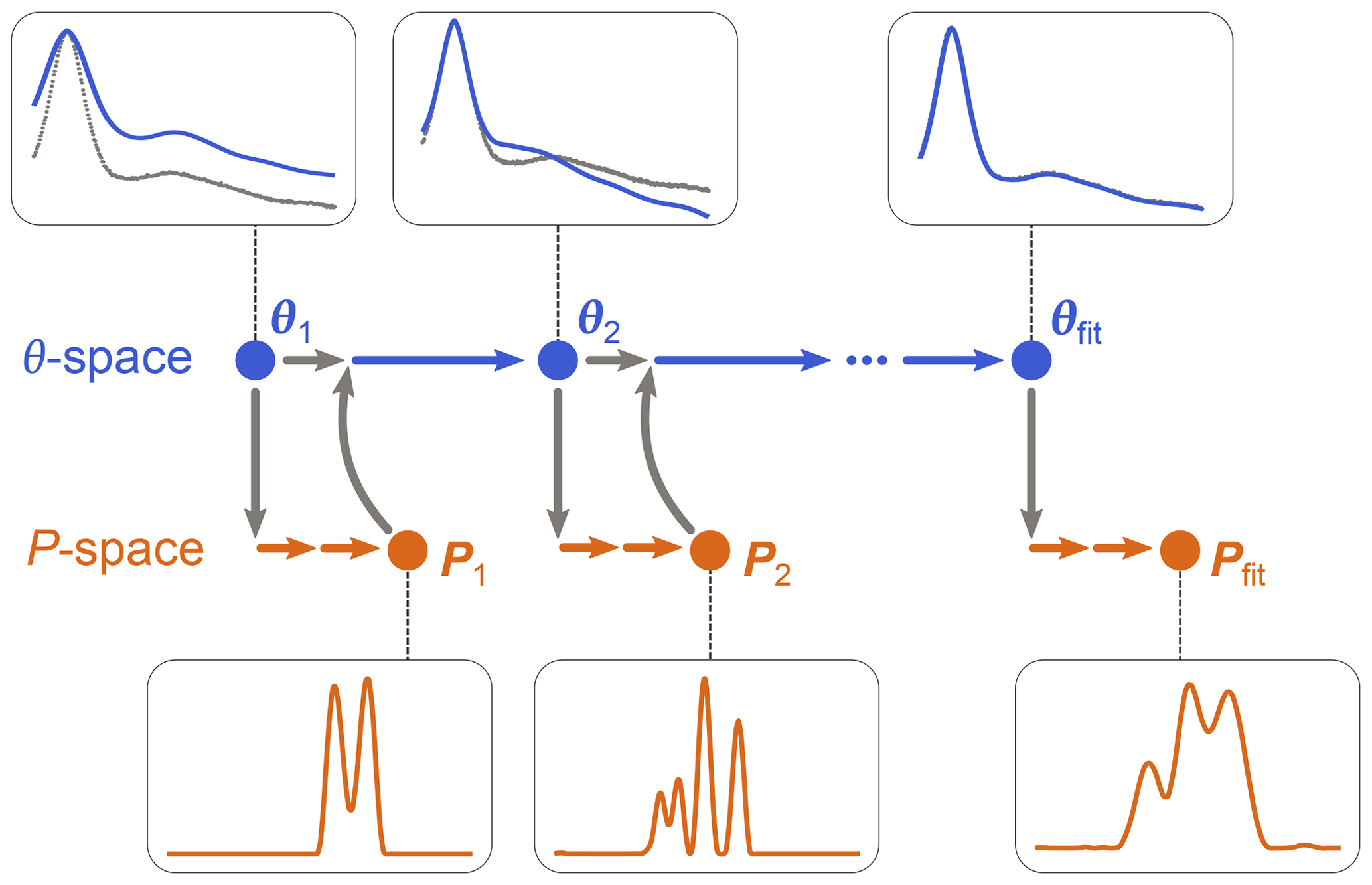
Figure 3One-step analysis of dipolar signals using separable non-linear least-squares optimization. A set of parameters θn (blue) is computed by optimization of Eq. (18) for some given experimental signal Vexp (grey dots). For each θn, a corresponding distance distribution Pn (orange) is computed by optimization of Eq. (19). This procedure is repeated until a minimum of the objective function is found for an optimal parameter set θfit, leading to the corresponding optimal distribution Pfit.
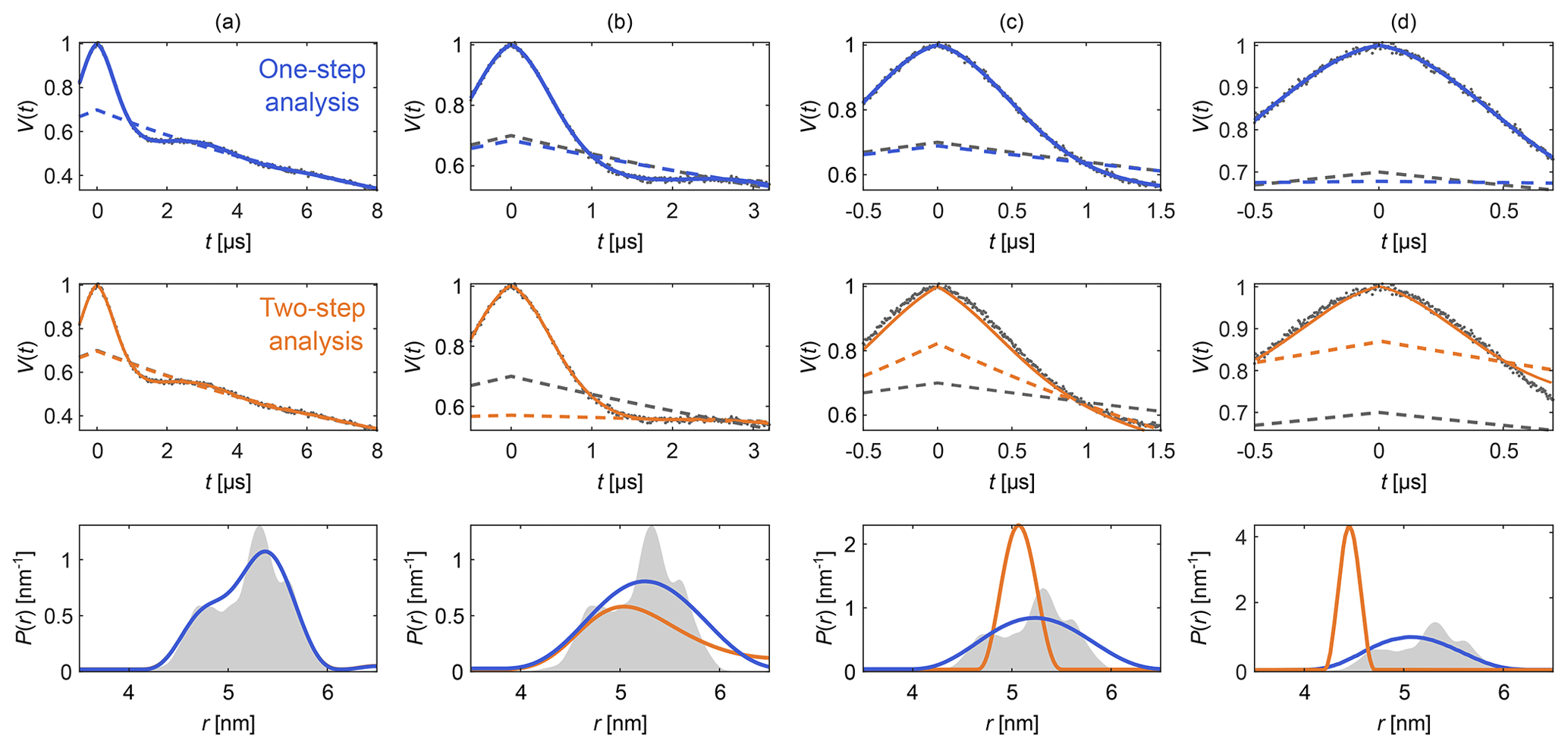
Figure 4Comparison of one-step and two-step analysis. A stretched-exponential background and a non-parametric distance distribution were fit to a simulated four-pulse DEER signal. The analysis was done by either fitting both simultaneously (blue) or by fitting the background followed by the distribution (two-step analysis, orange). The analysis was repeated on the same signal with increasing truncation (a–d). The two-step analysis fails in case (d). The data are given as grey dots, and the fitted signal and background are given as solid and dashed colored lines, respectively. The true background is given as a grey dashed line for reference. The non-parametric distance distributions obtained via Tikhonov regularization are given as, respectively, colored lines and the ground truth as a shaded area.
Figure 4 shows an example that compares this one-step approach to the traditional two-step analysis, using progressively more truncated dipolar signals. Analogous comparisons between two-step analysis and fully parametric models have been previously reported (Brandon et al., 2012; Stein et al., 2015). For a sufficiently long signal (Fig. 4a) both approaches yield similar results, as the signal is long enough for the oscillations to decay, facilitating the separate fit of the background in the two-step analysis. If the signal is truncated as in Fig. 4b–d, the two-step analysis cannot properly fit the background anymore. In contrast, one-step analysis correctly identifies the background in all cases and recovers the underlying non-parametric distance distribution with reasonable fidelity. It is important to keep in mind that highly truncated signals such as the ones shown in Fig. 4d can fail to provide correct results if the measurement noise is too large (see Fig. S2 in the Supplement).
This shows that DeerLab's ability to simultaneously fit the background and a non-parametric distribution opens up the possibility of fitting non-parametric distance distributions to signals which might have been deemed unanalyzable in the past.
Dipolar EPR spectroscopy found widespread use with four-pulse DEER. Since then, experimental dipolar EPR spectroscopy has developed into a set of diverse techniques, with signals exhibiting a variety of features. However, the data processing has not evolved much from its four-pulse DEER origins.
The key operator in the analysis is the dipolar kernel K(t,r) (see Eq. 2). It represents the experiment; i.e., it describes how the time-domain signal is obtained from a given distance distribution. If the kernel cannot account for a feature in the signal, it is because the kernel model is incomplete. In these cases, it is preferable to improve the kernel rather than to tweak the signal into an artificial four-pulse DEER signal.
One example of this is RIDME, where it is known that the measured signals in systems contain overtones not present in four-pulse DEER (Razzaghi et al., 2014). If disregarded, these overtones cause distortions in the distance distribution if the four-pulse DEER kernel is used to analyze the data. This can be avoided by including the overtones in the model (Keller et al., 2017). In DeerLab, one can include a set of overtones with a background in the kernel model, which can be used to directly fit primary RIDME data via, e.g., regularization.
Other examples are multi-pulse DEER sequences, which generally are not fully modeled. All multi-pulse DEER experiments feature modulations in addition to the basic modulation of Eq. (3). Despite their clear dipolar origin, these are regarded as undesirable “artifacts”: the “2+1 artifact” in four-pulse DEER (Jeschke, 2012; Teucher and Bordignon, 2018) and “artifacts” or “residues” in five-pulse and seven-pulse DEER (Borbat et al., 2013; Spindler et al., 2015; Breitgoff et al., 2017b, a; Doll and Jeschke, 2017; Milikisiyants et al., 2018). Several experimental and processing approaches have been published that aim to remove these contributions from the total signal to recover the idealized dipolar evolution function (Borbat et al., 2013; Spindler et al., 2015; Teucher and Bordignon, 2018; Breitgoff et al., 2017b, a). These approaches introduce further experimental or theoretical complexity.
However, these additional contributions are actual dipolar signals. They may even provide strong oscillations at times when the oscillations from the main signal have decayed, thus increasing the signal-to-noise ratio of the experiment. Instead of removing these contributions due to the lack of a proper model, it is advantageous to extend the model to explicitly include these contributions.
DeerLab includes such an extended model for multi-pulse DEER, derivable from spin density matrix dynamics. In this model, which we call the dipolar multi-pathway model, the overall signal is a combination of several dipolar signals arising from dipolar pathways of varying amplitudes and refocusing times (Salikhov et al., 1981; Kutsovsky et al., 1990; Kattnig et al., 2013; Borbat et al., 2013; Spindler et al., 2015). The total signal is given by Eq. (2) with the general kernel
where Λ0 is the total contribution of the unmodulated dipolar pathways, the index p runs over all N modulated dipolar pathways, Tp are the refocusing times of the individual modulated dipolar pathways, λp are the amplitudes of the modulated dipolar pathways, np are the harmonics of the individual modulated pathways, and the background function is as in Eq. (6). A schematic representation is shown in Fig. 5. The kernel for standard four-pulse DEER from Eq. (3) is a special case of Eq. (20), with N=1, T1=0, n1=1 , and λ1=λ.
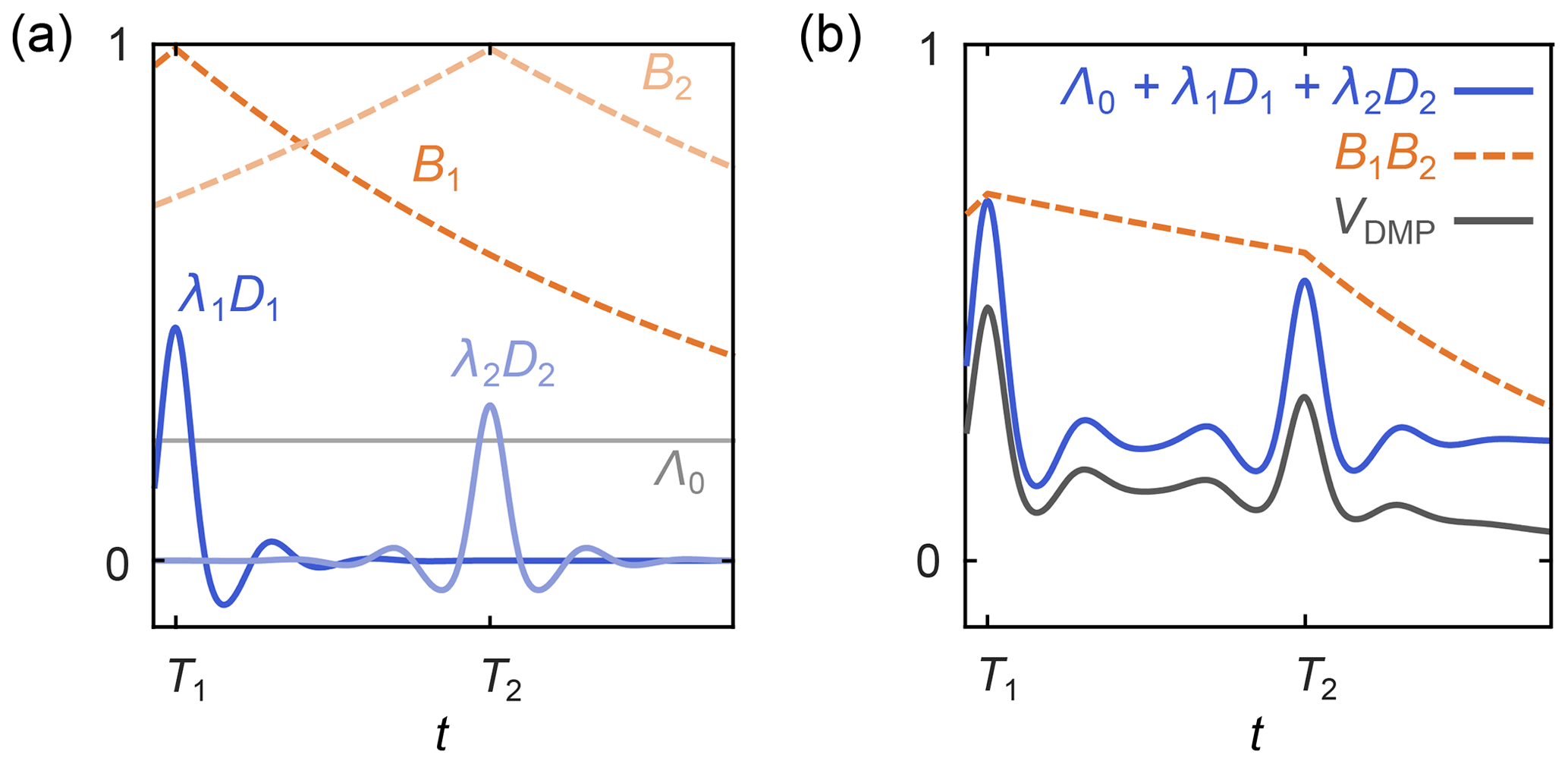
Figure 5Schematic representation of a dipolar multi-pathway DEER signal. (a) Background decays (orange dashed lines) and dipolar evolution functions (blue solid lines) are shown for two different dipolar pathways. The unmodulated component Λ0 is given as a solid grey line. (b) The overall signal (black) is given by the sum over all pathway dipolar evolution functions (blue) times the product over all pathway background decays (orange).
Discretization of the kernel in Eq. (20) gives the same expression as in Eq. (7),
with the parameter set θ comprising Λ0, all λp, np, Tp, as well as κd and d.
Figure 6 shows examples of how DeerLab can analyze multi-pulse DEER data in terms of a multi-pathway model, thus alleviating the need for experimental correction protocols or signal pre-processing (beyond phase correction). Note that experimental schemes which generate multiple datasets with some pathways shifted with respect to each other (Breitgoff et al., 2017a) can profit from global analysis (vide infra) to stabilize the accurate estimation of pathway parameters.
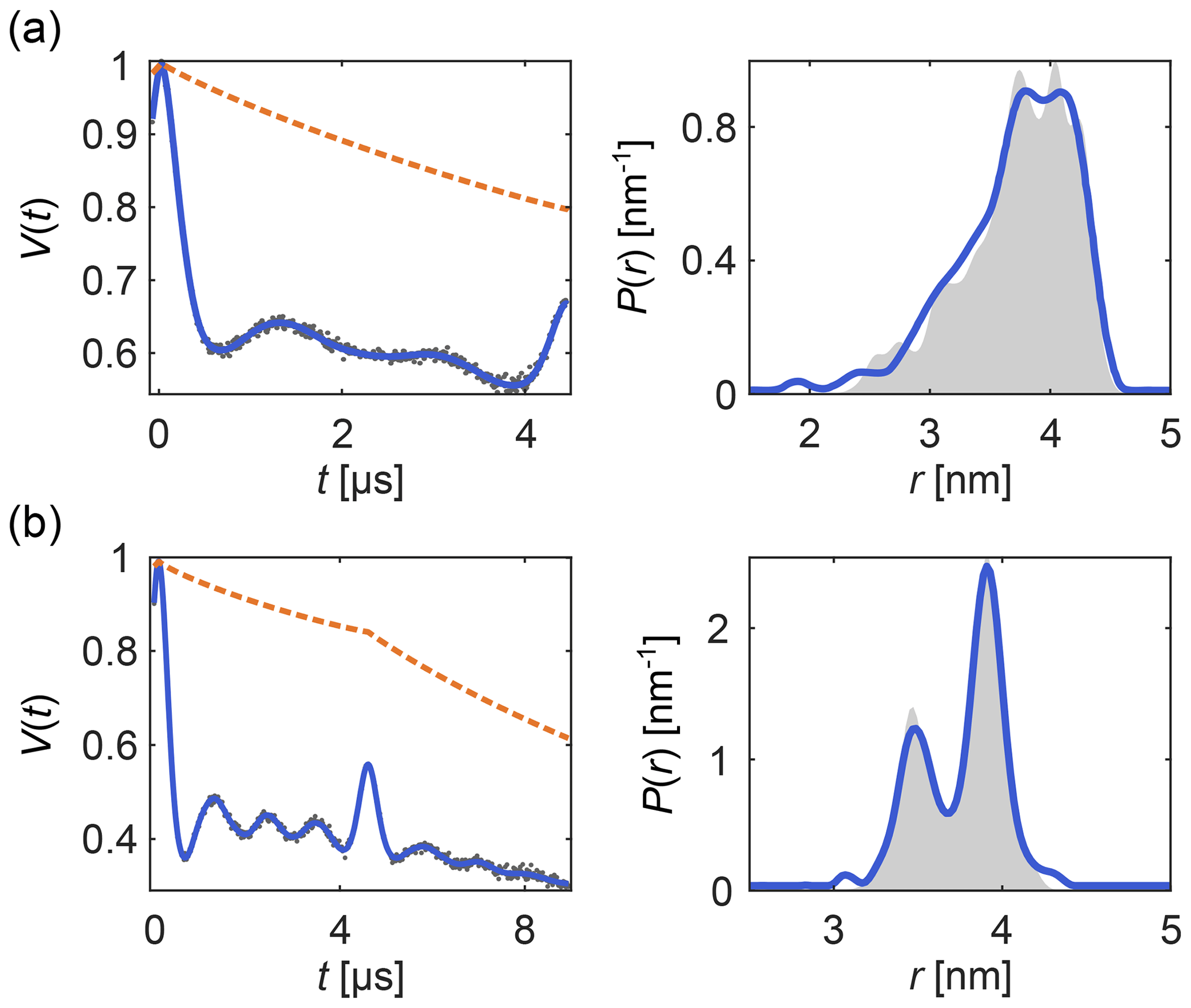
Figure 6One-step analysis of multi-pulse DEER signals with the dipolar multi-pathway model for (a) four-pulse DEER with the “2+1 artifact” and (b) five-pulse DEER with its four-pulse “artifact”. All data were fit with two modulated dipolar pathways. The data are given as grey dots, the signal and distribution fits are given as solid blue lines, the background fit is given as an orange dashed line, and the ground truth is given as a shaded area.
This analysis of multi-pulse DEER signals shows the benefits of using full models for dipolar signals instead of removing or avoiding “artifacts” to try to match partial models. DeerLab provides a compact framework for testing, developing, and applying more complete models.
Global analysis denotes the situation where a single model is fit simultaneously to multiple datasets. In dipolar EPR, this was first used for fitting a multi-Gauss distribution model to several DEER datasets (Brandon et al., 2012). Later, Tikhonov regularization was employed to fit short and long DEER traces simultaneously (Rein et al., 2018).
Global analysis is implemented in DeerLab for both parametric and non-parametric distance distribution models and for an arbitrary number of dipolar signals. The global optimization problem of a set of M dipolar signals Vexp,i using a model depending on parameters θ and on N non-parametric distance distributions Pj is
with and
with a similar expression without {P} and G({P}) for a fully parametric model. σi are the noise levels of the individual signals. The parameter vector θ includes the parameters needed to generate all signals Vi, where each Vi typically depends only on a subset of the parameters.
The quantities wi in Eq. (23) are the weights that determine the contribution of each signal to the objective function. The default is wi=1, meaning that each data point from each signal contributes equally, given its noise level, to the objective function. Different values of wi can be used to indicate preferential weighing.
If all signals Vi derive from a single distance distribution, then we can use Eq. (22) together with
or
Here, each Ki describes a different experiment (different pulse sequence, different trace length, etc.) and depends on a subset of the parameters in θ. The distance distribution P can be either parametric (in which case θ includes the distribution parameters) or it can be non-parametric. In the latter case, Eq. (22) is solved using separable non-linear least squares. As an example, in Fig. 7 we simultaneously fit a four-pulse DEER signal and a five-pulse DEER signal with its secondary four-pulse pathway contribution, using a model with a single non-parametric distribution but separate backgrounds and modulation depths for the two signals. The distance distribution underlying both signals is nicely recovered.

Figure 7Global analysis of a four-pulse DEER signal and a five-pulse DEER signal with its secondary four-pulse pathway contribution, both derived from the same distance distribution. The simulated data are given as grey dots, the ground truth distribution is given as a shaded area, and the signal and distribution fits are given as solid blue lines.
Note, however, that the analysis of dipolar signals of different length or obtained under different dynamical decoupling conditions may be inconsistent if different conformers have different dephasing rates (Baber et al., 2015).
Another common global analysis situation is when the measured signals stem from several samples containing a mixture of chemical or structural components, each with its own distinct distribution, and related to each other via additional conditions such as a chemical equilibrium. The simplest case is a system equilibrated between two forms A and B (A⇌B), e.g., a protein–ligand binding equilibrium or a monomer–dimer equilibrium. In this case, the dipolar signals are described as
with both component distributions PA and PB being fitted along the parameter set via Eq. (22). The mole fractions xA,i depend on the location of the equilibrium, which might vary among the samples via ligand concentration, matrix composition, and other factors. Either the mole fractions or the underlying equilibrium constant can be included among the fitting parameters.
Such titration or dose–response datasets have been analyzed using multi-Gaussian distribution models for the component distributions (Stein et al., 2015; Martens et al., 2016; Collauto et al., 2017; Barth et al., 2018; Jagessar et al., 2020). As discussed above, however, non-parametric distributions may often be a preferable choice. DeerLab enables global fitting of an arbitrary number of datasets with regularization approaches and, thus, analysis of titration datasets in terms of non-parametric distributions. As an example, Fig. 8 shows such an analysis of a protein–ligand binding assay, using signals with different noise levels, trace lengths, backgrounds, and modulation depths (Fig. 8a) with a model that includes the bound-protein mole fractions among the parameters. The global analysis gives good fits to the time-domain data and results in two non-parametric distributions that capture the underlying ground truth well (Fig. 8b). The extracted mole fractions are consistent with the underlying binding equilibrium (Fig. 8c). Alternatively, one can skip the separate determination of the mole fractions and include the dissociation constant directly as a parameter in the global analysis of the dipolar data. Even in cases where one or both extremes of the binding curve are experimentally unavailable, such an analysis is still feasible albeit at the cost of larger uncertainty in the fitted molar fraction or dissociation constants. In summary, this example shows that DeerLab allows global analysis of titration datasets using non-parametric distributions.
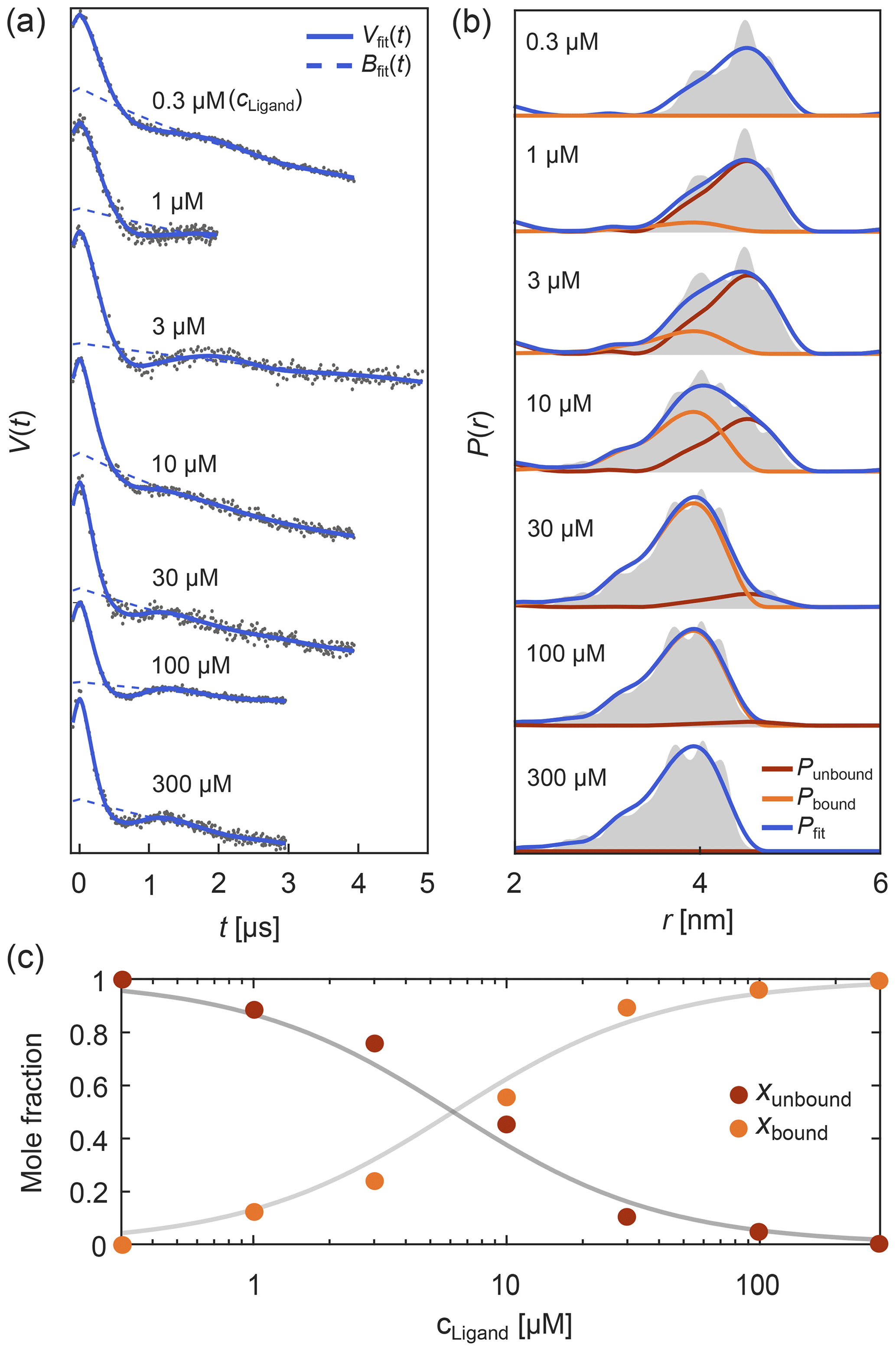
Figure 8Global fitting of titration data of a protein–ligand binding equilibrium with non-parametric distributions. In panel (a) four-pulse DEER traces with different trace lengths, modulation depths, backgrounds, and noise levels were simulated for different ligand concentrations added to a protein concentration of 1 µM. These parameters as well as the mole fractions of bound/unbound protein for each trace and two non-parametric distance distributions for the bound and unbound states (via Tikhonov regularization) were fit simultaneously. The simulated data are given as grey dots and the fitted signals and backgrounds are given as solid and dashed blue lines, respectively. In panel (b) the distance distribution fits for the unbound (red) and bound (orange) states are given as well as the combined fitted distribution (blue) for the different ligand concentrations. The ground truth sum distributions are given as grey shaded areas. In panel (c) the fitted mole fractions of the unbound (red) and bound (orange) states are given as colored dots. The solid grey lines represent the ground truth for a dissociation constant of Kd=5.65 µM.
Even when a fitted model agrees with the experimental data and a minimum of the objective function has been located, it does not mean that the only or the best fit has been found. The objective function can have multiple minima, meaning that the located minimum is not necessarily the global minimum (see Fig. 9). Which minimum is found depends mainly on where the search is started. The boundaries set on the parameter space can also influence the outcome if a minimum is located outside these boundaries. Other factors, e.g., the numerical algorithms and convergence parameters used for the optimization, can affect this as well.
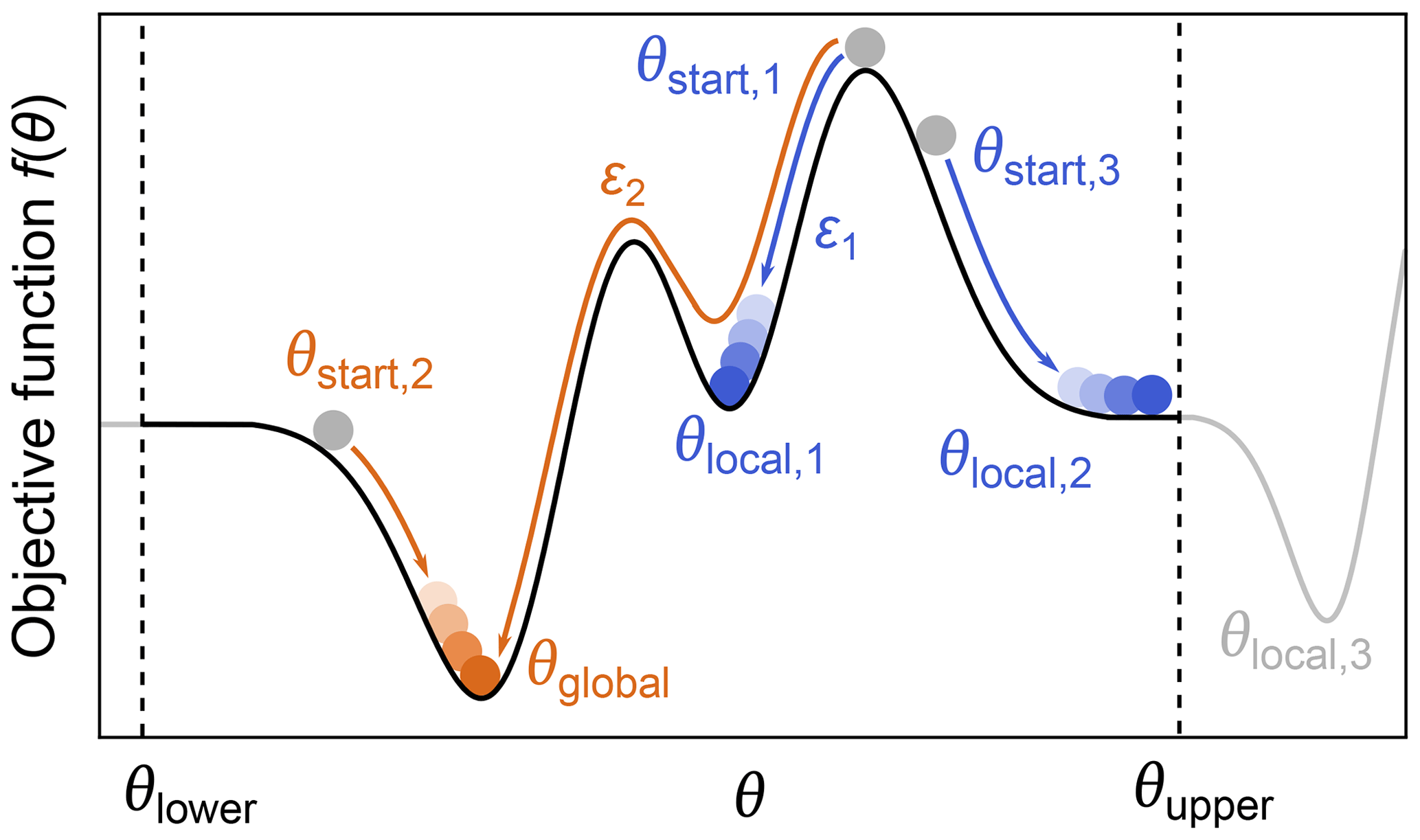
Figure 9Global vs. local minima. During optimization of a parameter θ, by minimization of an objective function f(θ) (black line), several local minima (blue) might be found instead of the global minimum (orange). The global minimum can be found by varying the starting point, the lower/upper boundaries θupper and θlower (to find minima which might be outside the bounds, e.g., θlocal,3), or the convergence parameters ε of the numerical solver such that some local minima might be ignored.
While there are dedicated global optimization algorithms, the simplest approach to find a global minimum is to repeat the optimization process with different starting values in order to explore the parameter space more fully (Sen et al., 2007). After sampling enough starting points, a set of minima is found and the one with the lowest objective function value is taken as the global minimum (see Fig. 9).
While these procedures can be costly, it is recommended to routinely check that variation of algorithmic parameters does not yield a lower minimum.
After obtaining a fitted model, an important step is to assess the goodness of the fit. If the fit is not good, either the optimization failed to locate an appropriate minimum (see previous section) or the model is inapplicable (e.g., oversimplified) for the given experimental data, and a better model needs to be used.
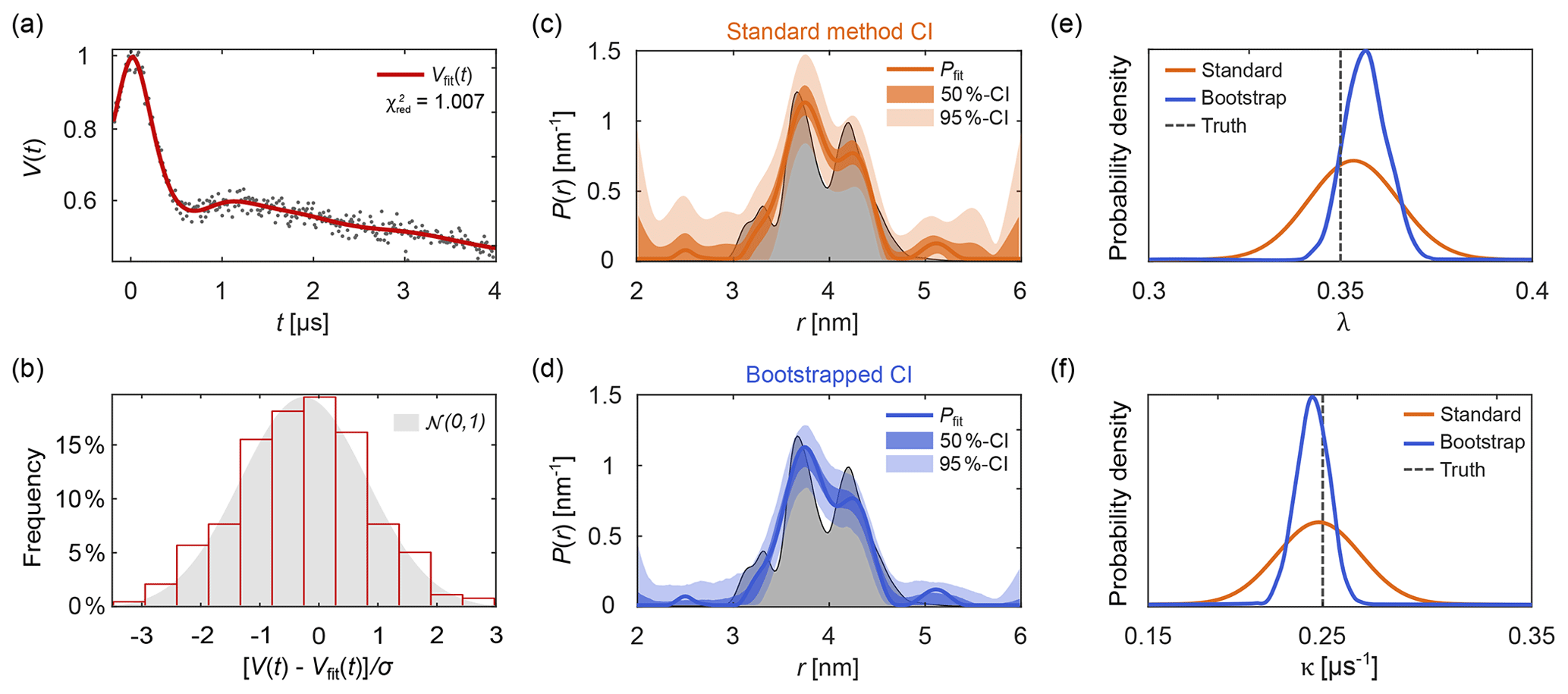
Figure 10Uncertainty analysis. In panel (a) a simulated noisy four-pulse DEER signal with exponential background (grey dots) is fitted with a non-parametric distance distribution (red line). In panel (b), the red bars show the histogram of normalized residual values and the reference standard Gaussian distribution as a grey shaded area. In panels (c) and (d) the fitted distance distribution is given as blue/orange lines as well as the 50 % and 95 % confidence intervals (shaded areas) obtained via the standard method (orange, top) and via bootstrapping (blue, bottom). The ground truth distribution is shown as a shaded grey area for reference. The estimated distribution of the fitted modulation depth λ (e) and background decay rate constant κ (f) obtained via the standard method are given as orange lines. The kernel density estimations obtained via bootstrapping are given as blue lines. The true values of λ and κ are given as a dashed grey line for reference. All bootstrap results were obtained from 1000 bootstrap samples and the regularization parameter was optimized using AIC for the original signal and fixed throughout the analysis.
To assess the goodness of fit, several procedures can be utilized. A direct test is to compare the histogram of the normalized residuals to the standard normal distribution 𝒩(0,1). Here, σ is the noise standard deviation estimated either from a dataset with several, individually stored scans (Edwards and Stoll, 2016), from the standard deviation of the (flat) imaginary part of the signal, or from the residuals of the signal minus the fitted model. Accuracy of the estimate of σ decreases in the sequence indicated, due to a possible imbalance in quadrature channels and the slight model inadequacy that is unavoidable for ill-posed problems. An example of this is shown in Fig. 10b. If the histogram deviates strongly from a Gaussian distribution, the fit is considered inadequate. Alternatively, the comparison can also be based on a statistical test.
Another method is to examine the reduced χ2-value:
Here, Ndof is the number of degrees of freedom, which can be taken as approximately equal to the number of data points minus the number of model parameters. A good fit is characterized by . Note that the use of for non-linear models is not rigorous. Also, the notion of (effective) number of parameters for a non-parametric distribution model, estimated as with defined in Eq. (11), is not straightforward (Edwards and Stoll, 2016).
Additional methods for assessing goodness of fit are discussed in Budil et al. (1996) and Hansen et al. (2012).
Up to this point, we took advantage of knowing the ground truth when we assessed quality of the solutions. However, in experimental work the ground truth is unknown. The presence of noise in experimental signals introduces uncertainty about the underlying noise-free dipolar signal and results in uncertainty about the model parameters. This, in turn, affects the strength of the conclusions that can safely be drawn. For example, nm supports much more confident conclusions about r0 than nm. It is therefore crucial to always report uncertainty estimates for all fitted parameters and distance distributions extracted from experimental data, for model parameters θi as well as vector elements Pj of non-parametric distance distributions. Reporting fitted values without accompanying uncertainty estimates is meaningless. Several approaches have been proposed for uncertainty estimation, including validation of the regularization model (Jeschke et al., 2006; Altenbach, 2020), iterative scanning of the χ2-surface (Brandon et al., 2012; Stein et al., 2015), covariance matrices (Stein et al., 2015; Hustedt et al., 2018), and Bayesian inference (Edwards and Stoll, 2016; Sweger et al., 2020).
DeerLab provides two separate methods for uncertainty estimation for both model parameters θi and for vector elements Pj of non-parametric distance distributions.
The first method estimates parameter uncertainties from the covariance matrix (Budil et al., 1996). For a fully parametric model with parameter vector θ, this is well established (Hustedt et al., 2018). The covariance matrix for θ is
where J is the Jacobian matrix of derivatives with elements evaluated at θ=θfit and is calculated using numerical differentiation.
There is also a simple way to obtain the covariance matrix ΣP for the elements of a non-parametric P determined via regularization, but only if the non-negativity constraint for P is disregarded. It is obtained by propagating the time-domain noise covariance matrix σ2I (see Eq. 8) to the distance domain by (Weese, 1992; Kasper et al., 2002)
with defined in Eq. (11). Note that this can be utilized even for models that depend on other parameters, since V always depends linearly on P, as shown above.
From the covariance matrices in Eqs. (28) and (29), the standard errors of a parameter θi or a distribution vector element Pi are obtained as
and
These are used to estimate symmetric confidence intervals (CIs) around the fitted parameter for a confidence level γ with boundaries
and
where zγ is the γ-quantile of a standard normal or Student's t-distribution.
This method for estimating CIs is simple and stands on a sound theoretical basis. However, it has several limitations. (1) It approximates the parameter likelihood by a Gaussian distribution centered around the fitted θfit and Pfit. While this is often a reasonable approximation, it can still fail in many cases. (2) It assumes that the parameters are unbounded. This is not fulfilled in the analysis of dipolar signals, as most parameters are constrained to a certain range, e.g., and Pi≥0. Although the boundary conditions can be imposed by cropping the CIs in Eq. (31) to the parameter range (Wang, 2008), the calculation of the CIs is still based on an unbounded assumption. Hence, the CIs do not include the additional information provided by the constraints. (3) In the case of a model that depends on both parameters θ and a non-parametric distribution P, the covariances between θi and Pj are not accounted for, potentially leading to underestimation of uncertainties.
A more general and accurate method for the estimation of parameter uncertainty involves bootstrapping (Efron and Tibshirani, 1986; Banks et al., 2010). This is a Monte Carlo resampling method based on generated synthetic signals with different noise realizations. The variant implemented in DeerLab first generates N synthetic traces Vk by adding N different noise realizations to the fitted model V[θfit,Pfit]. The noise is drawn from a Gaussian distribution with standard deviation σ estimated from the experimental data. Then, the N bootstrap traces Vk are analyzed in the same fashion as the original dataset Vexp, resulting in N+1 fitted parameter vectors θfit,k and distance distributions Pfit,k. The distributions of the parameter values and the distance distribution vector elements are then taken as approximations of the underlying parameter uncertainty distributions.
The bootstrap method, while costly, has several important advantages over the method based on covariance matrices. All information provided by parameter constraints is included in the estimation. Additionally, model-free estimations of parameter distributions are obtained, without the need to assume a Gaussian distribution. These can be statistically analyzed in multiple ways to quantify the parameter uncertainty. For example, in analogy to above, one can define the confidence interval for a parameter θ with confidence level as
where and θα∕2 are the th and (α∕2)th percentiles of the bootstrapped θ distribution.
Figure 10 shows an example of parameter uncertainty estimation using both the standard method and bootstrap. Although both methods lead to similar confidence intervals, the bootstrapped solution provides narrower intervals thanks to the use of the additional information provided by parameter boundaries and the non-negativity constraint P≥0. While the standard method provides an easily accessible uncertainty estimation, the use of bootstrapping is recommended for producing final results.
While the distance distribution and its uncertainty analysis provide the complete information of the data, in application work it is often of interest to determine summarizing quantities such as the distance mode, the mean distance, or the standard deviation of the distance distribution. It is important to report uncertainties for these quantities as well. If the uncertainty analysis is based on covariance matrices, these uncertainties can be calculated from the covariance matrices ΣP and Σθ using error propagation via the Jacobian. For instance, the variance of the mean distance is
where J is the Jacobian containing the derivatives of with respect to all model parameters (θ and P). Note that this method does not work for the distance mode. In general, it is preferable to use the more accurate bootstrap method to determine the distance mode, mean, median, and similar quantities. The means and uncertainties of these quantities are easily calculated from their histograms obtained from the ensembles of fitted θ and P.
The above uncertainty analysis is performed under the assumption of a specific model for the distance distribution (parametric or non-parametric), the background, and the experiment. All estimated uncertainties capture variability only within this assumed model. The possibility that the data could be explained equally well, or better, by other models is not incorporated.
Model selection approaches, as outlined above for parametric and non-parametric distance distribution (selection of number of Gaussians, regularization parameter selection), provide convenient quantitative decision criteria for picking one distribution model over another in a principled fashion. On the other hand, background models are often chosen ad hoc. Finally, the choice of the standard DEER experiment model in Eq. (3) is based on physical assumptions (no orientation selection, no bandwidth limitations, no conformer-dependent phase memory times, no exchange couplings, etc.) that might not all be fully valid for a given experimental situation. Whether principled or ad hoc, any model selection eliminates model uncertainty from the analysis and leads to bias.
It is therefore preferable to compare and report the relative performance of a series of plausible models, without picking a winner. This can be accomplished using Akaike weights, defined as (Burnham and Anderson, 2003)
where ΔAIC,i is the difference between the AIC value of model i and the lowest AIC value within the set of models. The Akaike weights give the probability that model i is the best among the set of M candidate models, given the data. This can be used to compare a set of different parametric models or to compare a series of non-parametric distribution models differing in the regularization parameter α.
Figure 11a illustrates this for a set of parametric models differing in complexity (number of components) and type of basis function. The analysis finds Akaike weights of about 25 % for the 2-Gauss, 3-Gauss and 1-skewed Gauss models, indicating that the data do not provide enough evidence to clearly identify a best model. Figure 11b shows a comparison for non-parametric distribution models obtained with different α-values, where the AIC is calculated using (Edwards and Stoll, 2018). It is apparent that models over a range of α-values are similarly likely. Therefore, in neither case is there a clear “winner” model. Note that uncertainty in the regularization parameter α could also be propagated to the resulting distance distribution and thereby included in the confidence bands. In cases where this is not applicable, and depending on the conclusions that one wants to draw, it may be prudent to list all models that fit the data reasonably well as opposed to picking the model with the highest weight.
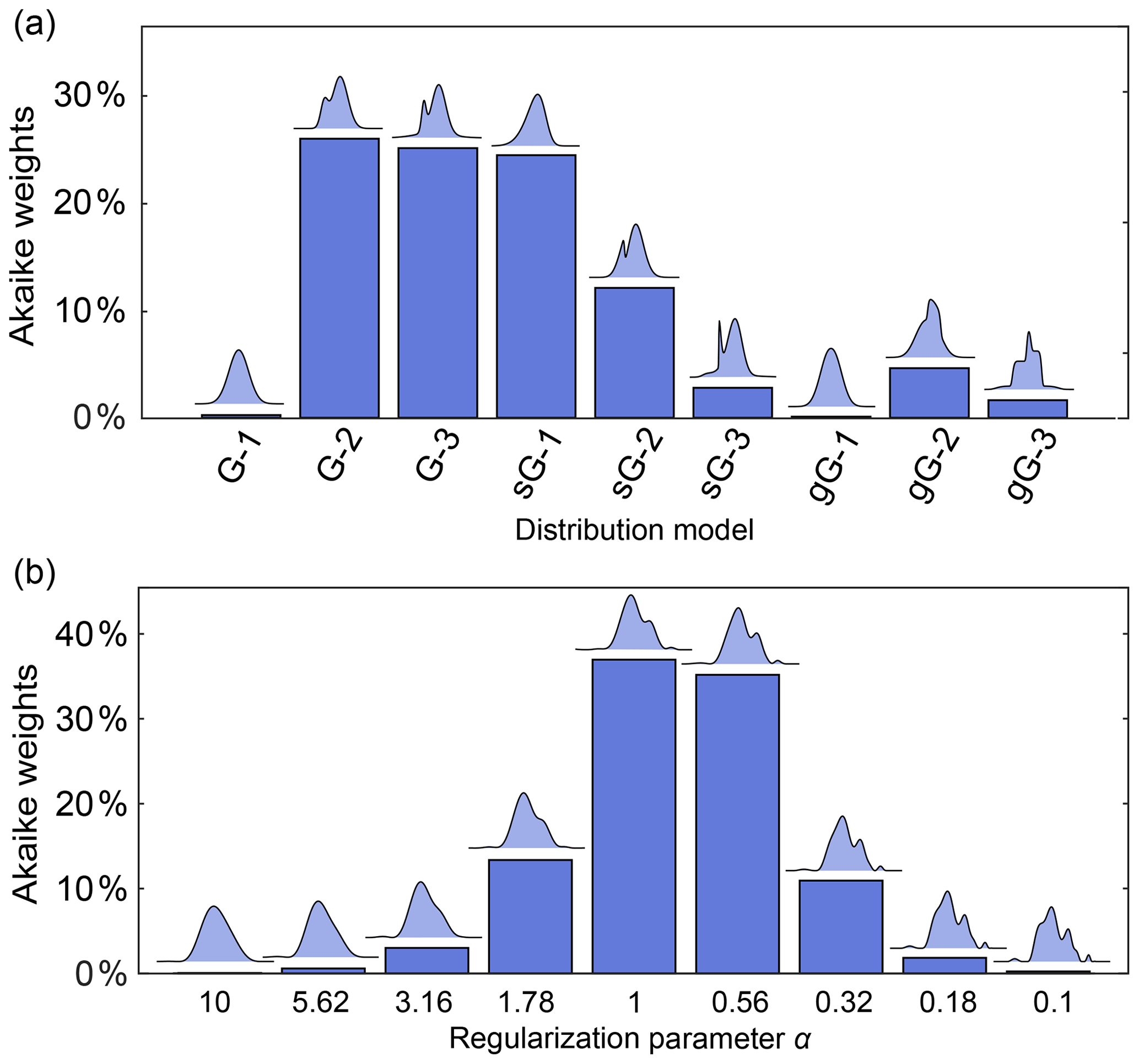
Figure 11Model comparison using Akaike weights. The Akaike weights (in percentages) are given for (a) a set of parametric distance distribution models with varying number n of ordinary (G-n), skewed (sG-n) and generalized (gG-n) Gaussians and (b) for non-parametric distance distributions determined over a set of values for the regularization parameter α. For each model in panels (a) and (b), the corresponding distance distribution is shown above the bar. Panels (a) and (b) are based on different simulated DEER signals of different distributions.
Despite these simple numerical procedures for model comparison, researchers need to use careful judgment in which models are included in a comparison and explicitly disclose the reasoning behind all model choices. Also, if the correct model is not included, then even such model comparison will lead to biased or incorrect conclusions.
Dipolar EPR spectroscopy requires reliable and robust data processing tools. The associated software should also be flexible and adaptable to quickly incorporate new developments in the field. DeerLab collects many existing as well as several novel data analysis methods in a flexible, robust, and reliable manner.
By allowing analysis workflows to be shared, DeerLab provides a significant step towards solving reproducibility issues plaguing dipolar EPR spectroscopy analysis. With DeerLab, the analysis scripts can be provided along with published data, leading to improved reproducibility. Through an online repository (see “Code availability” below), all DeerLab versions remain available, further enhancing reproducibility.
DeerLab can serve as a powerful method development tool. It allows the discovery and testing of new processing techniques. We illustrated this by introducing several extensions: one-step analysis with non-parametric distributions, the dipolar multi-pathway model, global analysis with non-parametric distribution models, and uncertainty estimation using bootstrap. The discussion of new methods or comparisons between established ones based on statistical arguments is also largely facilitated by such a scriptable tool.
Although DeerLab does not come with a GUI, it can serve as the data processing engine for intuitive and dedicated GUI-based data analysis tools. These are essential for the robust and successful application of routine dipolar EPR spectroscopy in fields such as structural biology or materials science.
In conclusion, DeerLab provides a unified and extensible open-source platform for data analysis in dipolar EPR spectroscopy, opening up a new world of data processing workflows.
The version of the DeerLab source code used for this paper is available at http://doi.org/10.5281/zenodo.4058605. Further information, examples, and documentation can be found there.
All DeerLab (version 0.10.0) scripts employed for generating the figures in this work are available in the Supplement. The supplement related to this article is available online at: https://doi.org/10.5194/mr-1-209-2020-supplement.
LFI and StS designed and implemented the software. All the authors contributed to all parts of the manuscript.
The authors declare that they have no conflict of interest.
This work was supported by the ETH Zurich (grant ETH-35 18-2, Gunnar Jeschke, Luis Fábregas Ibáñez), by the National Institutes of Health (grants GM125753 and GM127325, Stefan Stoll), and by the National Science Foundation (grant CHE-1452967, Stefan Stoll).
This research has been supported by the ETH Zurich (grant no. ETH-35 18-2), the National Institutes of Health, National Institute of General Medical Sciences (grant no. GM125753), the National Institutes of Health, National Institute of General Medical Sciences (grant no. GM127325), and the National Science Foundation, Division of Chemistry (grant no. CHE-1452967).
This paper was edited by Robert Bittl and reviewed by two anonymous referees.
Akaike, H.: A new look at the statistical model identification, IEEE T. Automat. Contr., 19, 716–723, https://doi.org/10.1109/TAC.1974.1100705, 1974. a
Altenbach, C.: LongDistances, available at: https://sites.google.com/site/altenbach/labview-programs/epr-programs/long-distances, last access: 27 September 2020. a, b, c, d
Baber, J. L., Louis, J. M., and Clore, G. M.: Dependence of Distance Distributions Derived from Double Electron–Electron Resonance Pulsed EPR Spectroscopy on Pulse-Sequence Time, Angew. Chem. Int. Edit., 54, 5336–5339, https://doi.org/10.1002/anie.201500640, 2015. a
Banks, H. T., Holm, K., and Robbins, D.: Standard error computations for uncertainty quantification in inverse problems: Asymptotic theory vs. bootstrapping, Math. Comput. Model., 52, 1610–1625, https://doi.org/10.1016/j.mcm.2010.06.026, 2010. a
Barth, K., Hank, S., Spindler, P. E., Prisner, T. F., Tampé, R., and Joseph, B.: Conformational Coupling and trans-Inhibition in the Human Antigen Transporter Ortholog TmrAB Resolved with Dipolar EPR Spectroscopy, J. Am. Chem. Soc., 140, 4527–4533, https://doi.org/10.1021/jacs.7b12409, 2018. a
Borbat, P. P. and Freed, J. H.: Dipolar Spectroscopy – Single-Resonance Methods, in: eMagRes, 465–494, available at: https://onlinelibrary.wiley.com/doi/abs/10.1002/9780470034590.emrstm1519, last access: 27 September 2020. a
Borbat, P. P., Georgieva, E. R., and Freed, J. H.: Improved Sensitivity for Long-Distance Measurements in Biomolecules: Five-Pulse Double Electron–Electron Resonance, J. Phys. Chem. Lett., 4, 170–175, https://doi.org/10.1021/jz301788n, 2013. a, b, c, d, e
Bowman, M. K., Maryasov, A. G., Kim, N., and DeRose, V. J.: Visualization of distance distribution from pulsed double electron–electron resonance data, Appl. Magn. Reson., 26, 23–39, https://doi.org/10.1007/BF03166560, 2004. a, b
Brandon, S., Beth, A. H., and Hustedt, E. J.: The global analysis of DEER data, J. Magn. Reson., 218, 93–104, https://doi.org/10.1016/j.jmr.2012.03.006, 2012. a, b, c, d, e, f, g
Breitgoff, F. D., Polyhach, Y. O., and Jeschke, G.: Reliable nanometre-range distance distributions from 5-pulse double electron electron resonance, Phys. Chem. Chem. Phys., 19, 15754–15765, https://doi.org/10.1039/C7CP01487B, 2017a. a, b, c
Breitgoff, F. D., Soetbeer, J., Doll, A., Jeschke, G., and Polyhach, Y. O.: Artefact suppression in 5-pulse double electron electron resonance for distance distribution measurements, Phys. Chem. Chem. Phys., 19, 15766–15779, https://doi.org/10.1039/C7CP01488K, 2017b. a, b
Bro, R. and Jong, S. D.: A fast non-negativity-constrained least squares algorithm, J. Chemometr., 11, 393–401, https://doi.org/10.1002/(SICI)1099-128X(199709/10)11:5<393::AID-CEM483>3.0.CO;2-L, 1997. a
Budil, D. E., Lee, S., Saxena, S., and Freed, J. H.: Nonlinear-Least-Squares Analysis of Slow-Motion EPR Spectra in One and Two Dimensions Using a Modified Levenberg–Marquardt Algorithm, J. Magn. Reson., Series A, 120, 155–189, https://doi.org/10.1006/jmra.1996.0113, 1996. a, b, c
Burnham, K. P. and Anderson, D. R.: Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach, Springer Science & Business Media, New York, 2003. a
Chen, D. and Plemmons, R. J.: Nonnegativity constraints in numerical analysis, in: The Birth of Numerical Analysis, World Sci., 109–139, https://doi.org/10.1142/9789812836267_0008, 2009. a
Chiang, Y.-W., Borbat, P. P., and Freed, J. H.: The determination of pair distance distributions by pulsed ESR using Tikhonov regularization, J. Magn. Reson., 172, 279–295, https://doi.org/10.1016/j.jmr.2004.10.012, 2005a. a, b, c
Chiang, Y.-W., Borbat, P. P., and Freed, J. H.: Maximum entropy: A complement to Tikhonov regularization for determination of pair distance distributions by pulsed ESR, J. Magn. Reson., 177, 184–196, https://doi.org/10.1016/j.jmr.2005.07.021, 2005b. a
Collauto, A., DeBerg, H. A., Kaufmann, R., Zagotta, W. N., Stoll, S., and Goldfarb, D.: Rates and equilibrium constants of the ligand-induced conformational transition of an HCN ion channel protein domain determined by DEER spectroscopy, Phys. Chem. Chem. Phys., 19, 15324–15334, https://doi.org/10.1039/C7CP01925D, 2017. a
Di Valentin, M., Albertini, M., Zurlo, E., Gobbo, M., and Carbonera, D.: Porphyrin Triplet State as a Potential Spin Label for Nanometer Distance Measurements by PELDOR Spectroscopy, J. Am. Chem. Soc., 136, 6582–6585, https://doi.org/10.1021/ja502615n, 2014. a
Doll, A. and Jeschke, G.: Double electron–electron resonance with multiple non-selective chirp refocusing, Phys. Chem. Chem. Phys.: PCCP, 19, 1039–1053, https://doi.org/10.1039/c6cp07262c, 2017. a, b
Domingo Köhler, S., Spitzbarth, M., Diederichs, K., Exner, T. E., and Drescher, M.: A short note on the analysis of distance measurements by electron paramagnetic resonance, J. Magn. Reson., 208, 167–170, https://doi.org/10.1016/j.jmr.2010.10.005, 2011. a
Dzuba, S. A.: The determination of pair-distance distribution by double electron–electron resonance: regularization by the length of distance discretization with Monte Carlo calculations, J. Magn. Reson., 269, 113–119, https://doi.org/10.1016/j.jmr.2016.06.001, 2016. a, b
Edwards, T. H. and Stoll, S.: A Bayesian approach to quantifying uncertainty from experimental noise in DEER spectroscopy, J. Magn. Reson., 270, 87–97, https://doi.org/10.1016/j.jmr.2016.06.021, 2016. a, b, c, d, e
Edwards, T. H. and Stoll, S.: Optimal Tikhonov regularization for DEER spectroscopy, J. Magn. Reson., 288, 58–68, https://doi.org/10.1016/j.jmr.2018.01.021, 2018. a, b, c
Efron, B. and Tibshirani, R.: Bootstrap Methods for Standard Errors, Confidence Intervals, and Other Measures of Statistical Accuracy, Stat. Sci., 1, 54–75, https://doi.org/10.1214/ss/1177013815, 1986. a
Fábregas Ibáñez, L. and Jeschke, G.: General regularization framework for DEER spectroscopy, J. Magn. Reson., 300, 28–40, https://doi.org/10.1016/j.jmr.2019.01.008, 2019. a, b, c, d
Fábregas Ibáñez, L. and Jeschke, G.: Optimal background treatment in dipolar spectroscopy, Phys. Chem. Chem. Phys., 22, 1855–1868, https://doi.org/10.1039/C9CP06111H, 2020. a, b, c
Fábregas Ibáñez, L., Jeschke, G., and Stoll, S.: DeerLab v0.11.0 (Version v0.11.0), Zenodo, https://doi.org/10.5281/zenodo.4058605, 2020.
Fitzkee, N. C. and Rose, G. D.: Reassessing random-coil statistics in unfolded proteins, P. Nat. A. Sci., 101, 12497–12502, https://doi.org/10.1073/pnas.0404236101, 2004. a
Freedman, D. A.: A Note on Screening Regression Equations, Am. Stat., 37, 152–155, https://doi.org/10.2307/2685877, 1983. a
Golub, G. and Pereyra, V.: Separable nonlinear least squares: the variable projection method and its applications, Inverse Probl., 19, R1–R26, https://doi.org/10.1088/0266-5611/19/2/201, 2003. a
Golub, G. H., Heath, M., and Wahba, G.: Generalized Cross-Validation as a Method for Choosing a Good Ridge Parameter, Technometrics, 21, 215–223, https://doi.org/10.1080/00401706.1979.10489751, 1979. a
Hansen, P. C.: The L-curve and its use in the numerical treatment of inverse problems, in: Computational Inverse Problems in Electrocardiology, ed. P. Johnston, Adv. Comp. Bioeng., WIT Press, 119–142, 2000. a
Hansen, P. C., Pereyra, V., and Scherer, G.: Least Squares Data Fitting with Applications, Johns Hopkins University Press, available at: https://muse.jhu.edu/book/21076, last access: 27 September 2020. a
Hintze, C., Bücker, D., Domingo Köhler, S., Jeschke, G., and Drescher, M.: Laser-Induced Magnetic Dipole Spectroscopy, J. Phys. Chem. Lett., 7, 2204–2209, https://doi.org/10.1021/acs.jpclett.6b00765, 2016. a
Hogben, H. J., Krzystyniak, M., Charnock, G. T. P., Hore, P. J., and Kuprov, I.: Spinach – A software library for simulation of spin dynamics in large spin systems, J. Magn. Reson., 208, 179–194, https://doi.org/10.1016/j.jmr.2010.11.008, 2011. a
Hurvich, C. M. and Tsai, C.-L.: Regression and time series model selection in small samples, Biometrika, 76, 297–307, https://doi.org/10.1093/biomet/76.2.297, 1989. a
Hustedt, E. J., Marinelli, F., Stein, R. A., Faraldo-Gómez, J. D., and Mchaourab, H. S.: Confidence Analysis of DEER Data and Its Structural Interpretation with Ensemble-Biased Metadynamics, Biophys. J., 115, 1200–1216, https://doi.org/10.1016/j.bpj.2018.08.008, 2018. a, b, c, d
Ionita, P., Volkov, A., Jeschke, G., and Chechik, V.: Lateral Diffusion of Thiol Ligands on the Surface of Au Nanoparticles: An Electron Paramagnetic Resonance Study, Anal. Chem., 80, 95–106, https://doi.org/10.1021/ac071266s, 2008. a
Jagessar, K. L., Claxton, D. P., Stein, R. A., and Mchaourab, H. S.: Sequence and structural determinants of ligand-dependent alternating access of a MATE transporter, P. Natl. A. Sci., 117, 4732–4740, https://doi.org/10.1073/pnas.1917139117, 2020. a
Jeschke, G.: DEER Distance Measurements on Proteins, Annu. Rev. Phys. Chem., 63, 419–446, https://doi.org/10.1146/annurev-physchem-032511-143716, 2012. a, b
Jeschke, G.: Dipolar Spectroscopy – Double-Resonance Methods, in: eMagRes, 1459–1476, https://doi.org/10.1002/9780470034590.emrstm1518, 2016. a
Jeschke, G.: MMM: A toolbox for integrative structure modeling, Protein Sci., 27, 76–85, https://doi.org/10.1002/pro.3269, 2018. a
Jeschke, G., Pannier, M., Godt, A., and Spiess, H. W.: Dipolar spectroscopy and spin alignment in electron paramagnetic resonance, Chem. Phys. Lett., 331, 243–252, https://doi.org/10.1016/S0009-2614(00)01171-4, 2000. a
Jeschke, G., Koch, A., Jonas, U., and Godt, A.: Direct Conversion of EPR Dipolar Time Evolution Data to Distance Distributions, J. Magn. Reson., 155, 72–82, https://doi.org/10.1006/jmre.2001.2498, 2002. a, b
Jeschke, G., Panek, G., Godt, A., Bender, A., and Paulsen, H.: Data analysis procedures for pulse ELDOR measurements of broad distance distributions, Appl. Magn. Reson., 26, 223–244, https://doi.org/10.1007/BF03166574, 2004. a, b
Jeschke, G., Chechik, V., Ionita, P., Godt, A., Zimmermann, H., Banham, J., Timmel, C. R., Hilger, D., and Jung, H.: DeerAnalysis2006—a comprehensive software package for analyzing pulsed ELDOR data, Appl. Magn. Reson., 30, 473–498, https://doi.org/10.1007/BF03166213, 2006. a, b, c, d, e
Kasper, v. W., Scales, J. A., William, N., and Luis, T.: Data and model uncertainty estimation for linear inversion, Geophys. J. Int., 149, 625–632, https://doi.org/10.1046/j.1365-246X.2002.01660.x, 2002. a
Kattnig, D. R. and Hinderberger, D.: Analytical distance distributions in systems of spherical symmetry with applications to double electron–electron resonance, J. Magn. Reson., 230, 50–63, https://doi.org/10.1016/j.jmr.2013.01.007, 2013. a
Kattnig, D. R., Reichenwallner, J., and Hinderberger, D.: Modeling Excluded Volume Effects for the Faithful Description of the Background Signal in Double Electron–Electron Resonance, J. Phys. Chem. B, 117, 16542–16557, https://doi.org/10.1021/jp408338q, 2013. a, b
Keller, K., Mertens, V., Qi, M., Nalepa, A. I., Godt, A., Savitsky, A., Jeschke, G., and Yulikov, M.: Computing distance distributions from dipolar evolution data with overtones: RIDME spectroscopy with Gd(III)-based spin labels, Phys. Chem. Chem. Phys., 19, 17856–17876, https://doi.org/10.1039/C7CP01524K, 2017. a
Kulik, L. V., Dzuba, S. A., Grigoryev, I. A., and Tsvetkov, Y. D.: Electron dipole–dipole interaction in ESEEM of nitroxide biradicals, Chem. Phys. Lett., 343, 315–324, https://doi.org/10.1016/S0009-2614(01)00721-7, 2001. a
Kutsovsky, Y. E., Mariasov, A. G., Aristov, Y. I., and Parmon, V. N.: Electron spin echo as a tool for investigation of surface structure of finely dispersed fractal solids, React. Kinet. Catal. L., 42, 19–24, https://doi.org/10.1007/BF02137612, 1990. a, b
Lawson, C. L. and Hanson, R. J.: Solving Least Squares Problems, vol. 18, SIAM, Prentice-Hall, Englewood Cliffs, New Jersey, USA, 1974. a
Lukacs, P. M., Burnham, K. P., and Anderson, D. R.: Model selection bias and Freedman’s paradox, Ann. I. Stat. Math., 62, 117, https://doi.org/10.1007/s10463-009-0234-4, 2009. a
Martens, C., Stein, R. A., Masureel, M., Roth, A., Mishra, S., Dawaliby, R., Konijnenberg, A., Sobott, F., Govaerts, C., and Mchaourab, H. S.: Lipids modulate the conformational dynamics of a secondary multidrug transporter, Nat. Struct. Mol. Biol., 23, 744–751, https://doi.org/10.1038/nsmb.3262, 2016. a
Matveeva, A. G., Nekrasov, V. M., and Maryasov, A. G.: Analytical solution of the PELDOR inverse problem using the integral Mellin transform, Phys. Chem. Chem. Phys., 19, 32381–32388, https://doi.org/10.1039/C7CP04059H, 2017. a
Milikisiyants, S., Voinov, M. A., and Smirnov, A. I.: Refocused Out-Of-Phase (ROOPh) DEER: A pulse scheme for suppressing an unmodulated background in double electron-electron resonance experiments, J. Magn. Reson., 293, 9–18, https://doi.org/10.1016/j.jmr.2018.05.007, 2018. a, b
Milikisyants, S., Scarpelli, F., Finiguerra, M. G., Ubbink, M., and Huber, M.: A pulsed EPR method to determine distances between paramagnetic centers with strong spectral anisotropy and radicals: The dead-time free RIDME sequence, J. Magn. Reson., 201, 48–56, https://doi.org/10.1016/j.jmr.2009.08.008, 2009. a
Milov, A., Salikhov, K., and Shchirov, M.: Use of the Double Resonance in Electron Spin Echo Method for the Study of Paramagnetic Center Spatial Distribution in Solids, Sov. Phys.-Sol. State, 23, 565–569, 1981. a, b
Milov, A. D., Ponomarev, A. B., and Tsvetkov, Y. D.: Electron-electron double resonance in electron spin echo: Model biradical systems and the sensitized photolysis of decalin, Chem. Phys. Lett., 110, 67–72, https://doi.org/10.1016/0009-2614(84)80148-7, 1984. a
Milov, A. D., Maryasov, A. G., and Tsvetkov, Y. D.: Pulsed electron double resonance (PELDOR) and its applications in free-radicals research, Appl. Magn. Reson., 15, 107–143, https://doi.org/10.1007/BF03161886, 1998. a
Nickerson, R. S.: Confirmation Bias: A Ubiquitous Phenomenon in Many Guises, Rev. Gen. Psychol., 2, 175–220, https://doi.org/10.1037/1089-2680.2.2.175, 1998. a
Pannier, M., Schädler, V., Schöps, M., Wiesner, U., Jeschke, G., and Spiess, H. W.: Determination of Ion Cluster Sizes and Cluster-to-Cluster Distances in Ionomers by Four-Pulse Double Electron Electron Resonance Spectroscopy, Macromolecules, 33, 7812–7818, https://doi.org/10.1021/ma000800u, 2000a. a, b, c
Pannier, M., Veit, S., Godt, A., Jeschke, G., and Spiess, H. W.: Dead-Time Free Measurement of Dipole–Dipole Interactions between Electron Spins, J. Magn. Reson., 142, 331–340, https://doi.org/10.1006/jmre.1999.1944, 2000b. a
Pribitzer, S., Sajid, M., Hülsmann, M., Godt, A., and Jeschke, G.: Pulsed triple electron resonance (TRIER) for dipolar correlation spectroscopy, J. Magn. Reson., 282, 119–128, https://doi.org/10.1016/j.jmr.2017.07.012, 2017. a
Razzaghi, S., Qi, M., Nalepa, A. I., Godt, A., Jeschke, G., Savitsky, A., and Yulikov, M.: RIDME Spectroscopy with Gd(III) Centers, J. Phys. Chem. Lett., 5, 3970–3975, https://doi.org/10.1021/jz502129t, 2014. a
Rein, S., Lewe, P., Andrade, S. L., Kacprzak, S., and Weber, S.: Global analysis of complex PELDOR time traces, J. Magn. Reson., 295, 17–26, https://doi.org/10.1016/j.jmr.2018.07.015, 2018. a, b
Salikhov, K. M., Dzuba, S. A., and Raitsimring, A. M.: The theory of electron spin–echo signal decay resulting from dipole–dipole interactions between paramagnetic centers in solids, J. Magn. Reson., 42, 255–276, https://doi.org/10.1016/0022-2364(81)90216-X, 1981. a
Saxena, S. and Freed, J. H.: Double quantum two-dimensional Fourier transform electron spin resonance: Distance measurements, Chem. Phys. Lett., 251, 102–110, https://doi.org/10.1016/0009-2614(96)00075-9, 1996. a
Saxena, S. and Freed, J. H.: Theory of double quantum two-dimensional electron spin resonance with application to distance measurements, J. Chem. Phys., 107, 1317–1340, https://doi.org/10.1063/1.474490, 1997. a
Schwarz, G.: Estimating the Dimension of a Model, Ann. Stat., 6, 461–464, https://doi.org/10.1214/aos/1176344136, 1978. a
Sen, K. I., Logan, T. M., and Fajer, P. G.: Protein Dynamics and Monomer–Monomer Interactions in AntR Activation by Electron Paramagnetic Resonance and Double Electron–Electron Resonance, Biochemistry, 46, 11639–11649, https://doi.org/10.1021/bi700859p, 2007. a, b, c, d
Sima, D. M. and Van Huffel, S.: Separable nonlinear least squares fitting with linear bound constraints and its application in magnetic resonance spectroscopy data quantification, J. Comput. Appl. Math., 203, 264–278, https://doi.org/10.1016/j.cam.2006.03.025, 2007. a
Spindler, P. E., Waclawska, I., Endeward, B., Plackmeyer, J., Ziegler, C., and Prisner, T. F.: Carr–Purcell Pulsed Electron Double Resonance with Shaped Inversion Pulses, J. Phys. Chem. Lett., 6, 4331–4335, https://doi.org/10.1021/acs.jpclett.5b01933, 2015. a, b, c
Srivastava, M. and Freed, J. H.: Singular Value Decomposition Method to Determine Distance Distributions in Pulsed Dipolar Electron Spin Resonance, J. Phys. Chem. Lett., 8, 5648–5655, https://doi.org/10.1021/acs.jpclett.7b02379, 2017. a
Stein, R. A., Beth, A. H., and Hustedt, E. J.: Chapter Twenty – A Straightforward Approach to the Analysis of Double Electron–Electron Resonance Data, in: Methods in Enzymology, edited by Qin, P. Z. and Warncke, K., vol. 563 of Electron Paramagnetic Resonance Investigations of Biological Systems by Using Spin Labels, Spin Probes, and Intrinsic Metal Ions, Part A, 531–567, Academic Press, https://doi.org/10.1016/bs.mie.2015.07.031, 2015. a, b, c, d, e, f, g, h
Stoll, S. and Schweiger, A.: EasySpin, a comprehensive software package for spectral simulation and analysis in EPR, J. Magn. Reson., 178, 42–55, https://doi.org/10.1016/j.jmr.2005.08.013, 2006. a
Sugiura, N.: Further analysis of the data by Akaike' s information criterion and the finite corrections, Commun. Stat.-Theor. M., 7, 13–26, https://doi.org/10.1080/03610927808827599, 1978. a
Sweger, S. R., Pribitzer, S., and Stoll, S.: Bayesian Probabilistic Analysis of DEER Spectroscopy Data Using Parametric Distance Distribution Models, J. Phys. Chem. A, 124, 6193–6202, https://doi.org/10.1021/acs.jpca.0c05026, 2020. a, b
Teucher, M. and Bordignon, E.: Improved signal fidelity in 4-pulse DEER with Gaussian pulses, J. Magn. Reson., 296, 103–111, https://doi.org/10.1016/j.jmr.2018.09.003, 2018. a, b
Tikhonov, A. N.: Solution of incorrectly formulated problems and the regularization method, Soviet Math. Dokl., 4, 1035–1038, 1963. a
Timofeev, I. O., Krumkacheva, O. A., Fedin, M. V., Karpova, G. G., and Bagryanskaya, E. G.: Refining Spin–Spin Distance Distributions in Complex Biological Systems Using Multi-Gaussian Monte Carlo Analysis, Appl. Magn. Reson., 49, 265–276, https://doi.org/10.1007/s00723-017-0965-y, 2018. a, b
Wang, H.: Confidence intervals for the mean of a normal distribution with restricted parameter space, J. Stat. Comput. Sim., 78, 829–841, https://doi.org/10.1080/00949650701273902, 2008. a
Weese, J.: A reliable and fast method for the solution of Fredhol integral equations of the first kind based on Tikhonov regularization, Comput. Phys. Commun., 69, 99–111, https://doi.org/10.1016/0010-4655(92)90132-I, 1992. a
Wilhelm, J. and Frey, E.: Radial Distribution Function of Semiflexible Polymers, Phys. Rev. Lett., 77, 2581–2584, https://doi.org/10.1103/PhysRevLett.77.2581, 1996. a
Worswick, S. G., Spencer, J. A., Jeschke, G., and Kuprov, I.: Deep neural network processing of DEER data, Science Advances, 4, eaat5218, https://doi.org/10.1126/sciadv.aat5218, 2018. a
- Abstract
- Introduction
- Theoretical basics
- Current approaches
- One-step analysis
- Multi-pathway models
- Global analysis
- Global and local minima
- Goodness of fit
- Uncertainty analysis
- Model comparison
- Concluding remarks
- Code availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement
- Abstract
- Introduction
- Theoretical basics
- Current approaches
- One-step analysis
- Multi-pathway models
- Global analysis
- Global and local minima
- Goodness of fit
- Uncertainty analysis
- Model comparison
- Concluding remarks
- Code availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement